Imported Packages
import nltk
nltk.download('punkt')
import re
from gensim import models, corpora
from nltk import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from gensim import similarities
Select Descrition columns from train database
train_data = train['Description'].values.tolist()
Basic cleaning for NLP: stopwords removal, lemmatizer, etc.
#Load stopwords
stop_words = set(stopwords.words("english"))
#Lemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
def cleandata(review) :
clean_des = re.sub('[^a-zA-Z]', ' ', str(review)) # Remove punctuation/words not starting with alphabet
clean_des = clean_des.lower() # make words lower cases
words = word_tokenize(clean_des) # tokenize
words = [w for w in words if not w in stop_words] # stop words removal
words = [wordnet_lemmatizer.lemmatize(w) for w in words] #Lemmatize words
return words
Choose number of topics
# Define the number of topics
t = 10
cleaned = []
for description in train_data:
cleaned.append(cleandata(description))
# Create a Dictionary associate word to id
D = corpora.Dictionary(cleaned)
# Transform texts to numeric
corpra = [D.doc2bow(i) for i in cleaned]
LDA Model
lda = models.LdaModel(corpus=corpra, num_topics=t, id2word=D)
print('LDA model')
for index in range(0,t):
# top 9 topics
print("Topic Number %s:" % str(index+1), lda.print_topic(index, 9))
print("-" * 120)

LSI Model
lsi = models.LsiModel(corpus=corpra, num_topics=t, id2word=D)
print('LSI model')
for index in range(0,t):
# top 9 topics
print("Topic Number %s:" % str(index+1), lsi.print_topic(index, 9))
print("-" * 117)

Randomly pick one description from test to predict similarity.
import random
i = random.randint(1,3948) # since my test dataset has 3498 values
print(i)
test_data = Test.loc[i,'Description']
print('-----This is the description from test that I am going to predict:-----')
print(test_data)

LDA similarity
# compare LDA model and LSI model to predict similarity.
lda_i = similarities.MatrixSimilarity(lda[corpra])
m = D.doc2bow(cleandata(test_data))
# perform some queries
similar_lda = lda_i[lda[m]]
# Sort the similarities
LDA = sorted(enumerate(similar_lda), key=lambda item: -item[1])
# Top 10 most similar documents:
print(LDA[:10])
# the most similar document
doc_id, similarity = LDA[1]
print(train_data[doc_id][:100])
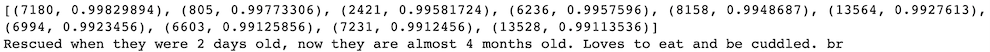
LSI similarity
# Do the same similarity queries by using LSI model
lsi_i = similarities.MatrixSimilarity(lsi[corpra])
similar_lsi = lsi_i[lsi[m]]
LSI = sorted(enumerate(similar_lsi), key=lambda item:-item[1])
print(LSI[:10])
doc_id_lsi, similarity_lsi = LSI[1]
print(train_data[doc_id][:1000])
