Data Cleaning process on description
# Define stopwords, lemmatizer, and data cleaning process
stop_words = set(stopwords.words("english"))
# Lemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
# Stemming
stemming = nltk.PorterStemmer()
def cleandata(review) :
clean_des = re.sub('[^a-zA-Z]', ' ', str(review)) # Remove punctuation/words not starting with alphabet
clean_des = clean_des.lower() # make words lower cases
words = word_tokenize(clean_des) # tokenize
words = [w for w in words if not w in stop_words] # stop words removal
words = [stemming.stem(word) for word in words] # Stemming
words = [wordnet_lemmatizer.lemmatize(w) for w in words] #Lemmatize words
return words
Multinominal Classification
- Code
from sklearn.naive_bayes import MultinomialNB
tfvec = tfidfV(stop_words='english', ngram_range=(1, 1), lowercase=False)
model = Pipeline([('vectorizer', tfvec),('rf', MultinomialNB(alpha=0.0))])
- Accuracy:
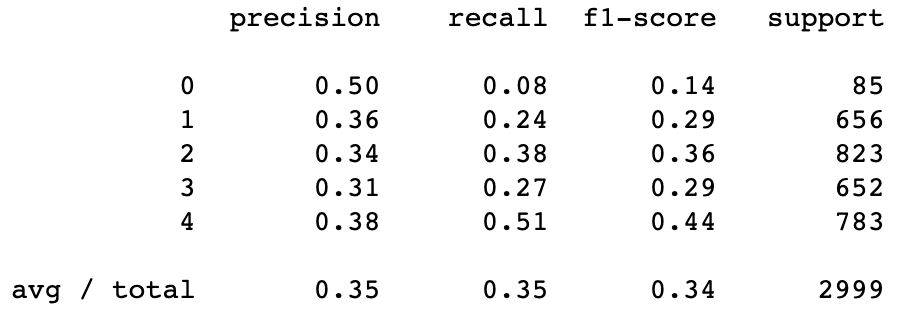
Analysis:
- Multinomial Naïve Bayes classifier is applied since it provides a nice baseline for several variants of a classifier, the multinomial variant will be the one most suitable for word counts. After load the description and adoption speed into ‘X’ and ‘y’ variables respectively with train and valid, the first thing needs to do is text preprocessing, such as tokenization, lower cases, lemmatizing. Stop-words removal is included in TF-IDF vectorizer, which computes relative frequency a word appears in the description and compared the frequency across all description in the dataset. Then fit the model, and the Multinomial Naïve Bayes model resulted in a score of 35% of accuracy.
- Classifiers tend to have some parameters, trying all different parameter is not possible to operate, however, it is feasible to run exhaustive searches of the best parameters on a grid of values, including all classifiers with bi-grams or monogram, with or without TF-IDF, or number of parameters, or number of depth in Random Forest.
Random Forest - 2-grams vectorizer
- Code
# define 2-gram vectorizer
cv_vectorizer = CountVectorizer(ngram_range=(2,2),analyzer=cleandata)
X_cv = cv_vectorizer.fit_transform(train['Description'])
X_cv_clf = pd.concat([train['length'], train['punctuation-percentage'],
pd.DataFrame(X_cv.toarray())], axis=1)
# find best model
rf = RandomForestClassifier()
param = {'n_estimators': [10, 150, 300],
'max_depth': [30, 60, 90, None]}
gs_cv = GridSearchCV(rf, param, cv=5, n_jobs=-1)# n_jobs=-1 for parallelizing search
gs_cv_fit = gs_cv.fit(X_cv_clf, train['AdoptionSpeed'])
gs_cs_df = pd.DataFrame(gs_cv_fit.cv_results_).sort_values('mean_test_score', ascending=False)
print(gs_cs_df.head(3))
# evaluate model
cv = CountVectorizer(ngram_range=(2,2),analyzer=cleandata) # defined before
cv_fit = cv.fit(X_train['Description'])
cv_train = cv_fit.transform(X_train['Description'])
cv_test = cv_fit.transform(X_test['Description'])
X_cv_train = pd.concat([X_train[['length', 'punctuation-percentage']].reset_index(drop=True),
pd.DataFrame(cv_train.toarray())], axis=1)
X_cv_test = pd.concat([X_test[['length', 'punctuation-percentage']].reset_index(drop=True),
pd.DataFrame(cv_test.toarray())], axis=1)
# Build model
rf_cv = RandomForestClassifier(n_estimators=300, max_depth=90, n_jobs=-1)
rf_model_cv = rf_cv.fit(X_cv_train, y_train)
y_prediction_cv = rf_model_cv.predict(X_cv_test)
precision, recall, fscore, train_support = f_score(y_test, y_prediction_cv, pos_label='spam', average='micro')
print('Precision: {} --- Recall: {} --- F1-Score: {} --- Accuracy: {}'.format(
round(precision, 3), round(recall, 3), round(fscore,3), round(accuracy(y_test,y_prediction_cv), 3)))
print(report(y_test, y_prediction_cv))
# plot confusion matrix
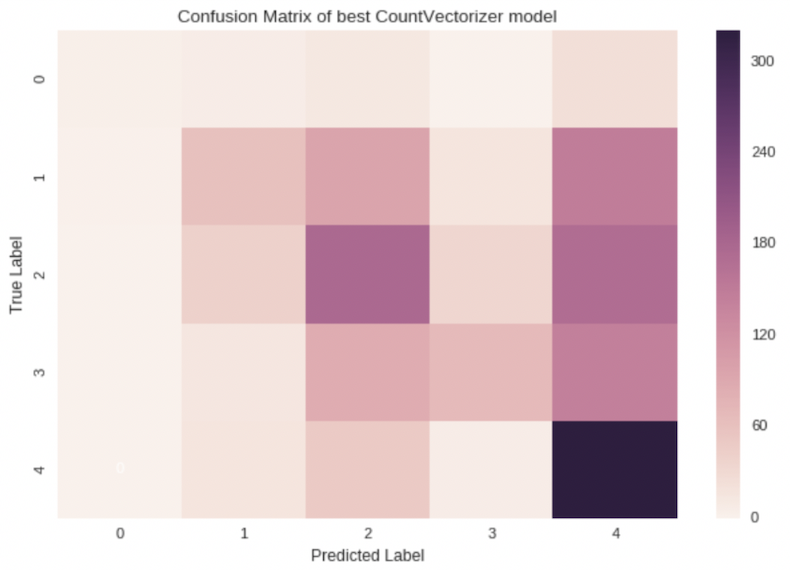
matrixcv = confusion_matrix(y_test, y_prediction_cv)
class_label = ['0','1','2','3','4']
matrixcv_df = pd.DataFrame(matrixcv, index=class_label,columns=class_label)
sns.heatmap(matrixcv_df, annot=True, fmt='d')
plt.title("Confusion Matrix of best CountVectorizer model")
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.show()
-
the ensemble model shows: n_estimator=300, max_depth=90 has the best result
-
Accuracy
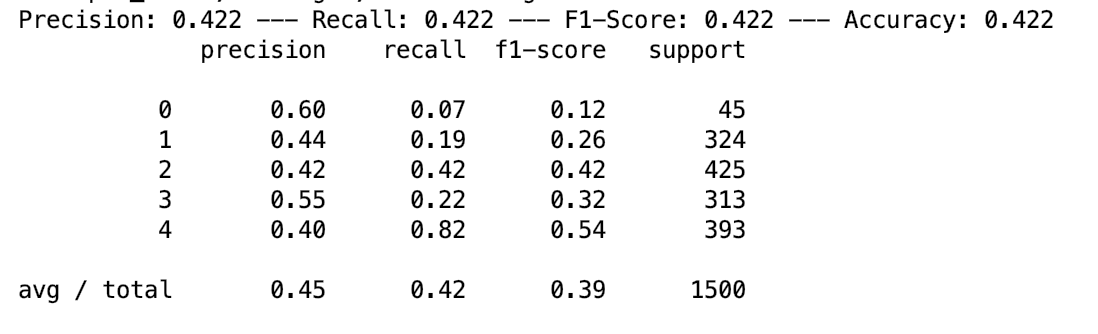
- Confusion Matrix
Random Forest - TF-IDF vectorizer
-
The ensemble model shows: n_estimator=300, max_depth=None has the best result
-
Accuracy
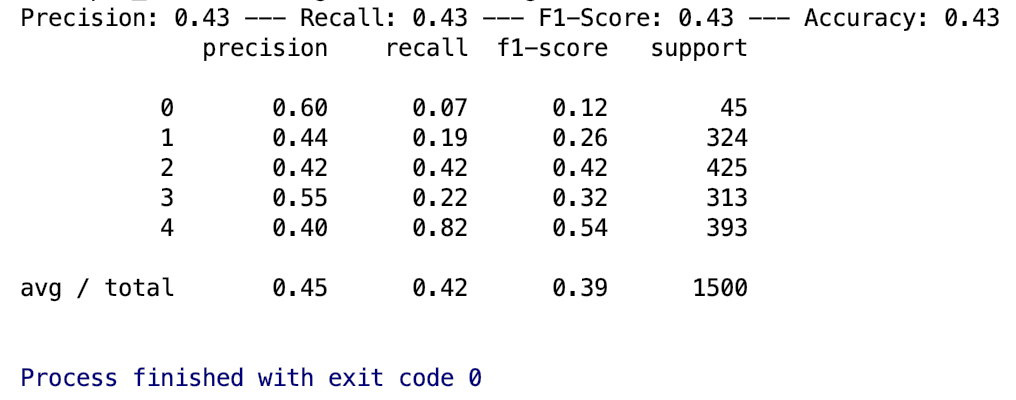
- Confusion Matrix
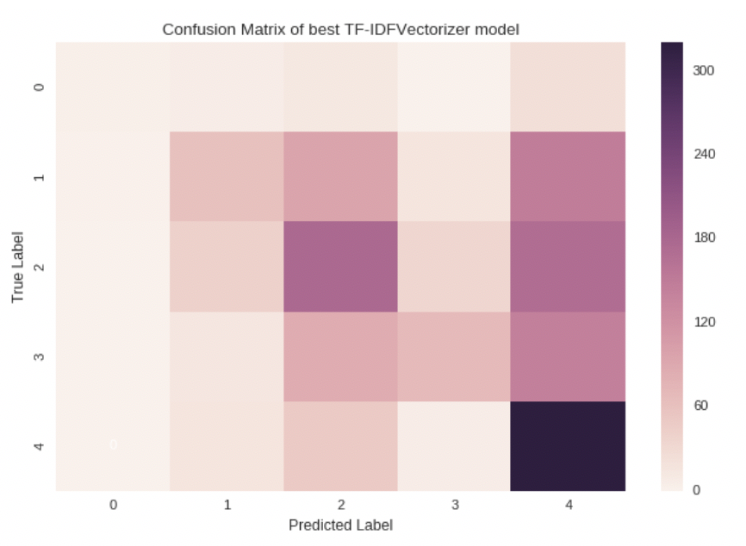
Analysis:
- After grid searching, the best parameters should apply to random forest from Bi-gram vectorizer has the number of estimators as 300 and the maximum number of levels in each decision tree as 90. However, the best parameters from TF-IDF vectorizer as 300 of trees with no maximum number of levels in each decision tree.
- The accuracy score of Random Forest Classifier from Bi-gram is 42.2%. The accuracy score of Random Forest Classifier from TF-IDF vectorizer is 43%.
- The confusion matrix indicates that the label4, which is no pet being adopted, predicted best among other labels, following by label2, which is adopted within 1 month.